About iBLab iBLab について
研究内容
研究活動
私たちの研究室では、モデル駆動型とデータ駆動型のアプローチを駆使した生命科学研究を異分野融合研究の立場から進めています。2つのアプローチの長所を最大限に発揮した解析、また、各々の弱点を補える統合的なアプローチの開発にも取り組んでいます。たとえば、現実世界で取得されたモダリティの異なるデータを統合することで、疾患進行や治療効果を高精度かつ定量的に予測する研究を進めています。さらに、実データと統計的に同じ性質を持つシミュレーションデータを大量に生成し、さまざまなシナリオをシミュレーションにより評価することで、仮想世界で得られた知見を現実世界にフィードバックする研究にも力を入れています。現実世界と仮想世界を縦横無尽に行き来するアプローチを確立し、新しい時代の異分野融合研究を創り出しています。

データサイエンスの”未開の地”である、時系列のデータ解析に適したモデル駆動型アプローチと1時点のデータ解析に適したデータ駆動型アプローチの統合を目指しています。また、リアルワールドとデジタルワールドをシミュレーションでリンクさせることで生命科学のデジタルツイン化を加速し、全く新しい研究スタイルを確立しています。
様々な階層にわたるデータの定量的特性をマルチスケールで解析するため、数理科学の理論と計算科学の技術開発に取り組んでいます。これにより、基礎研究から応用、実装に至るまで、多面的かつ異分野横断的な生物学研究を展開しています。ここでは、特に力を入れている研究テーマについて、トピックごとに説明します。
デジタルツイン技術を駆使した生命医科学研究
治療戦略の開発や感染症対策の最適化には、臨床試験やコホート研究において多大な時間と資金、労力が必要です。デジタルツイン技術を活用することで、数理モデル、シミュレーション、AI 技術を統合し、リアルワールドの患者データを再現します。これにより、現実の制約下では実施が難しい網羅的な介入シナリオや、病原体の存在や疾患の有無を検出するための検査体制および方法をデジタル空間で評価することが可能となります。また、シミュレーションを通じてさまざまな患者群における反応を予測し、効果的な治療戦略を早期に見出すことができます。
私たちは、実験および臨床研究で取得されるさまざまな階層のデータの情報を統合したデジタルツイン技術を駆使して、臨床試験に進む前に不適切な治療法や候補薬剤を特定し、最適な臨床試験のデザインを行うことで、開発プロセスを加速しています。また、個人レベルでの病態進行を考慮した感染症対策の評価を実現し、科学的根拠に基づいた知見を省庁に提供したり、医療従事者と連携して臨床対応指針やガイドラインの策定を支援したりしています。社会の喫緊課題である疾患を具体例として、数理科学による予測・精密・個別医療のパラダイムシフトに挑戦しています。
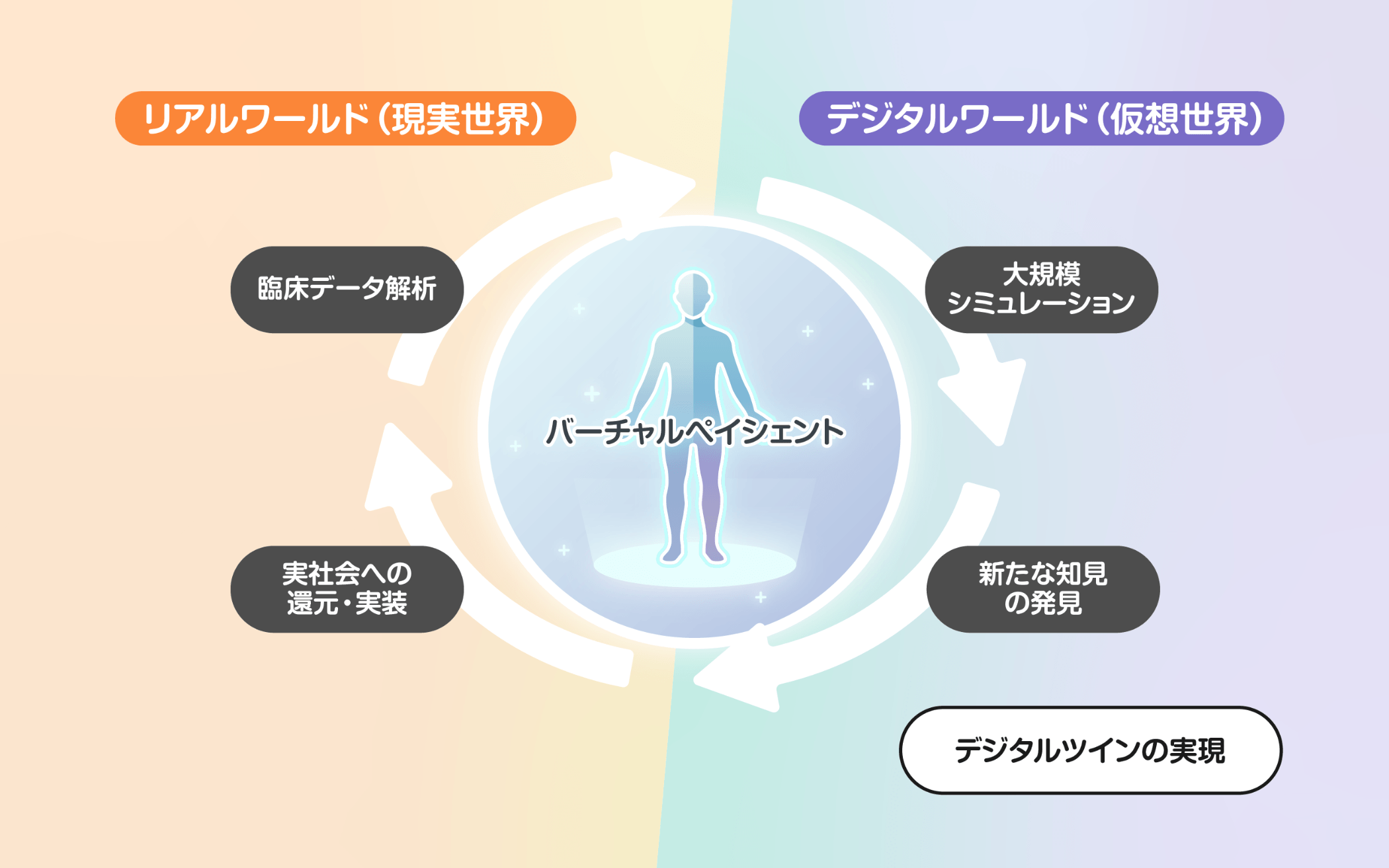
臨床データをモデル駆動型アプローチで解析し、実症例を特徴づけるパラメータ分布を推定します。その後、数理モデルやAI技術を活用して、現実世界の患者集団のデータと統計的に同一の性質を持つバーチャルペイシェント(virtual patient)と呼ばれるシミュレーションデータを生成します。このシミュレーションデータにデータ駆動型アプローチを適用することで、従来の統計分析では困難だった治療最適化に向けた患者層別化や、病態進行の予測といった新たな知見が発見できます。さらに、治療などの介入効果を考慮したシミュレーションを活用してバーチャルペイシェントを生成することで、臨床試験の詳細な設計が可能となり、薬剤開発の効率化や加速が期待できます。このようなアプローチにより、個別化医療や精密医療の発展を支援する基盤を構築しています。
患者層別化とバイオマーカー探索の研究
多くの疾患において、患者ごとに病態進行の程度は異なり、さらに併存疾患や治療の影響により同一患者内での病態進展も変化します。特に、患者個別の状況に応じた治療介入が求められますが、患者集団全体の平均に基づいた治療では効果が限られる場合があります。進歩するゲノム科学により精密医療が発展し、患者はバイオマーカーや遺伝子診断を通じてサブグループに分類(層別化)され、それぞれに適した治療法が選択されるアプローチが進められています。しかし、層別化の基準は明確ではなく、特に病態進行のダイナミックな変化を捉えることが難しいため、適切な層別化や個別化治療の実現には多くの課題が残されています。これらの課題を解決するためには、メカニズムが十分に説明され、適切な層別化や未来予測に基づく個別化治療を実施することが求められます。
私たちは、さまざまな医療機関と協力して、臨床的転帰が紐づいた血液検査や生化学データ、サイトカイン、既往歴、生活習慣、治療情報、脳 MRI、医療画像、アンケートなどをありとあらゆる臨床データに対し、また、それらの統合データに対して AI 技術を活用したデータ駆動的な患者層別化を実現し、病態進行の異なる“患者群”を特定するアプローチを開発しています。また、説明可能 AI を用いて、各症例が属する患者群を特徴づける臨床データ項目を探索し、それに基づいてバイオマーカー(群)を特定したり、臨床スコアを開発したりしています。さらに、特定されたバイオマーカー(群)の時間変化を記述する数理モデルを開発し、AI 技術と組み合わせることで、各症例の病態進行における個人レベルでの予後予測を実現可能にしています。
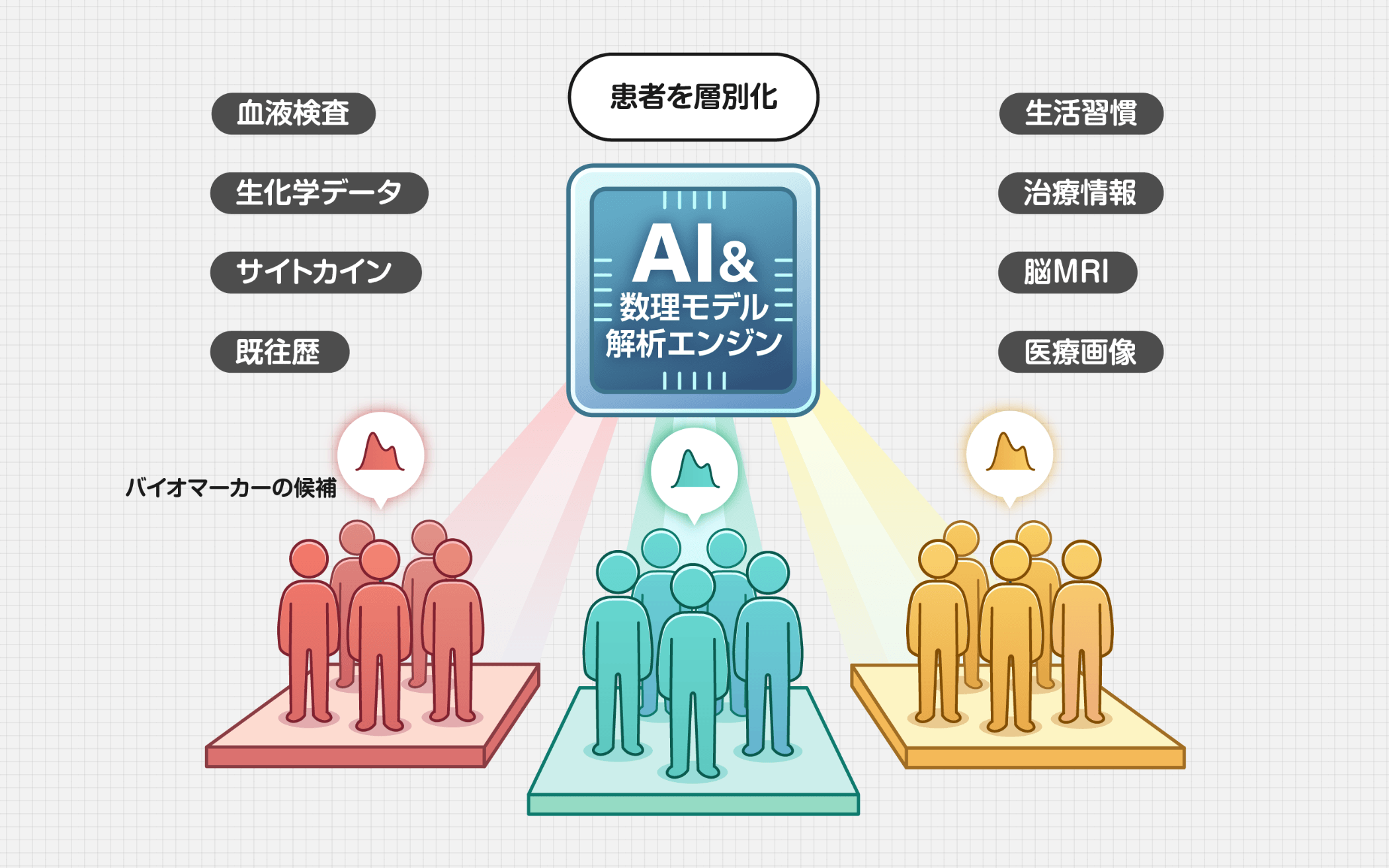
各種疾患に関する臨床データを後ろ向きに用いて、それぞれの症例がたどる病態進行のパターンをAI技術により予測し、層別化します。そして、再びAI技術を駆使して、層別化された症例群を予測する単一あるいは複数のバイオマーカーを特定します。特に、発症後から計測可能な経時的な非侵襲的臨床データを用いることで、数理モデルとAI技術を融合させることで可能な限り早期に病態進行パターンを予測できるようになります。
治療やワクチンの効果を定量的に評価する研究
治療薬は病気の進行を抑えたり、症状を緩和することで患者を健康な状態に戻そうとします。一方、ワクチンは液性免疫や細胞性免疫、免疫記憶等の免疫応答の誘導により、病原体の侵入を回避し、排除する働きを高めることで、個人レベルでの感染および発症、重症化の予防を実現し、さらに集団レベルで感染症の制御に貢献します。ただし、治療薬やワクチンの効果や反応性にはばらつきがあり、疾患の状態を反映するバイオマーカーの変動や個人差を理解した上で適切に使用する必要があります。たとえば、新型コロナウイルスに対する mRNA ワクチンでは、接種後に誘導される抗体量やその維持期間に個人差が大きく見られました。この「個人差」は、年齢、遺伝的背景、既往歴、基礎疾患の有無、さらには過去の感染経験など、さまざまな要因に基づいています。実際、ブレイクスルー感染の発生率は、ワクチン接種後の個々の免疫状態に大きく依存しており、個人ごとの免疫状態の時間変化を考慮したワクチン接種戦略が必要と考えられています。同様に、薬剤による治療効果についても、顕著な個人差が頻繁に報告されています。
私たちは、数理モデルと AI 技術を統合したアプローチを開発し、バイオマーカーの変動からこのような個人差を考慮した定量的なデータ解析を行っています。これにより、治療薬やワクチンの効果をデータ駆動的に層別化し、層別化されたグループごとの臨床情報や背景因子を参照して、効果の現れかたの定量的な理解や評価を実現しています。最終的には、これらの研究を通じて治療戦略の最適化やワクチン接種戦略の開発を支援し、感染症対策の向上に寄与することを目指しています。
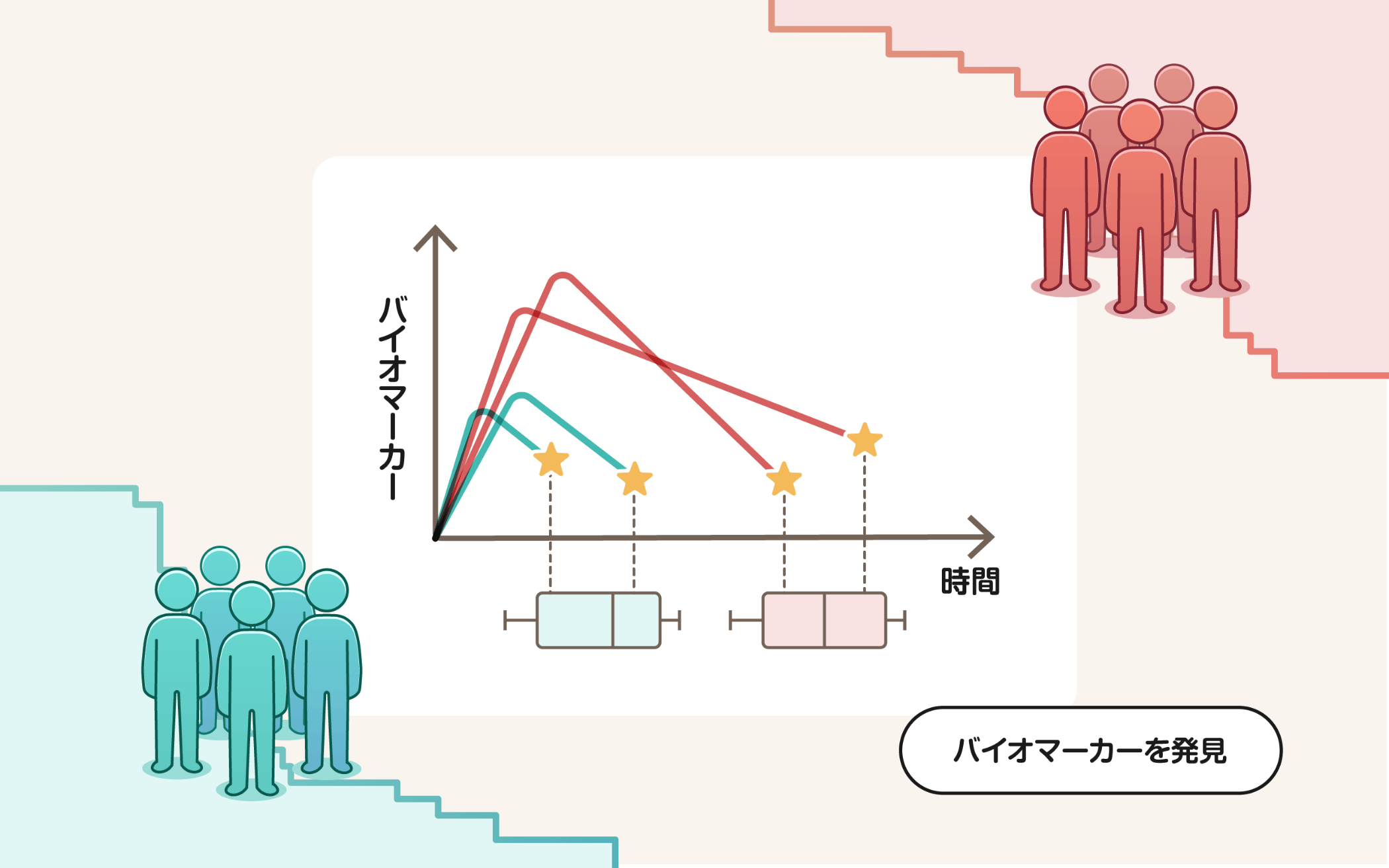
数理モデルを活用することで、治療薬やワクチン接種によって変化するさまざまなバイオマーカーを個人レベルで再構築することが可能となります。さらに、再構築された集団全体のバイオマーカーの動態にAI技術を適用することで、これらの時系列的な変化パターンを層別化することができます。層別化された各集団に対して、懸念されるイベントの発生を定量的かつ詳細に分析し、また、各集団のイベントに対するリスクが比較できます。加えて、これら集団について、さまざまな臨床情報と紐づけて解析することで、集団ごとの特徴を定量的に評価し、最適な治療やワクチン接種の戦略を策定することが可能になります。このような分析を通じて、多様なバイオマーカー動態を集団および個人レベルで理解し、さまざまに役立てるための基盤を提供することを目指しています。
新興・再興感染症の研究
近年、COVID-19 やエムポックスなどの新興・再興感染症が相次いで発生し、多くの国でアウトブレイクが起こっています。さらに、致死率の高いウイルス性出血熱や、自然宿主や媒介生物を介して感染する人獣共通感染症の発生も含め、グローバル化が進展し、国際的な人の移動が活発化したことにより、これまで国内での発生が確認されていない感染症についても輸入リスクが高まっています。つまり、海外で新興・再興感染症が発生した後、一定期間を経て日本国内に輸入例が生じ、その後国内で感染が拡大する可能性があるという構図です。感染流行を制御するには、感染者を早期に特定し、迅速に隔離することが求められます。日本では感染症法や検疫法に基づき、感染者の入院や隔離措置が行われていますが、理想的には、感染者の疫学的所見や感染性ウイルスの排出期間など、科学的根拠に基づいて適切に社会的負荷を軽減するための感染予防・管理が必要です。また、流行期においては、日常生活におけるマスクの着用やソーシャルディスタンシングといった、個々人の行動変容に依存した対策も、感染症拡大防止において重要な役割を果たします。
私たちは、現在、そして、次なる感染症のアウトブレイクやパンデミックを見据え、さまざまな感染症に汎用的に適用可能な数理モデルやコンピュータシミュレーションの枠組みを開発しています。特に、感染者のスクリーニング手法、隔離終了条件、感染症診断薬を用いたサーベイランス手法といった、感染症対策の戦略についての定量的な評価を行っています。また、パンデミックやアウトブレイクを通じて、ウイルスがどのように適応し、進化していくのかを実験および臨床データと合わせたシミュレーションにより分析しています。さらに、疫学およびウイルス学的なエビデンスに基づいた科学的アプローチによる、感染症対策の迅速かつ適切な立案や開発に資する研究にも取り組んでいます。
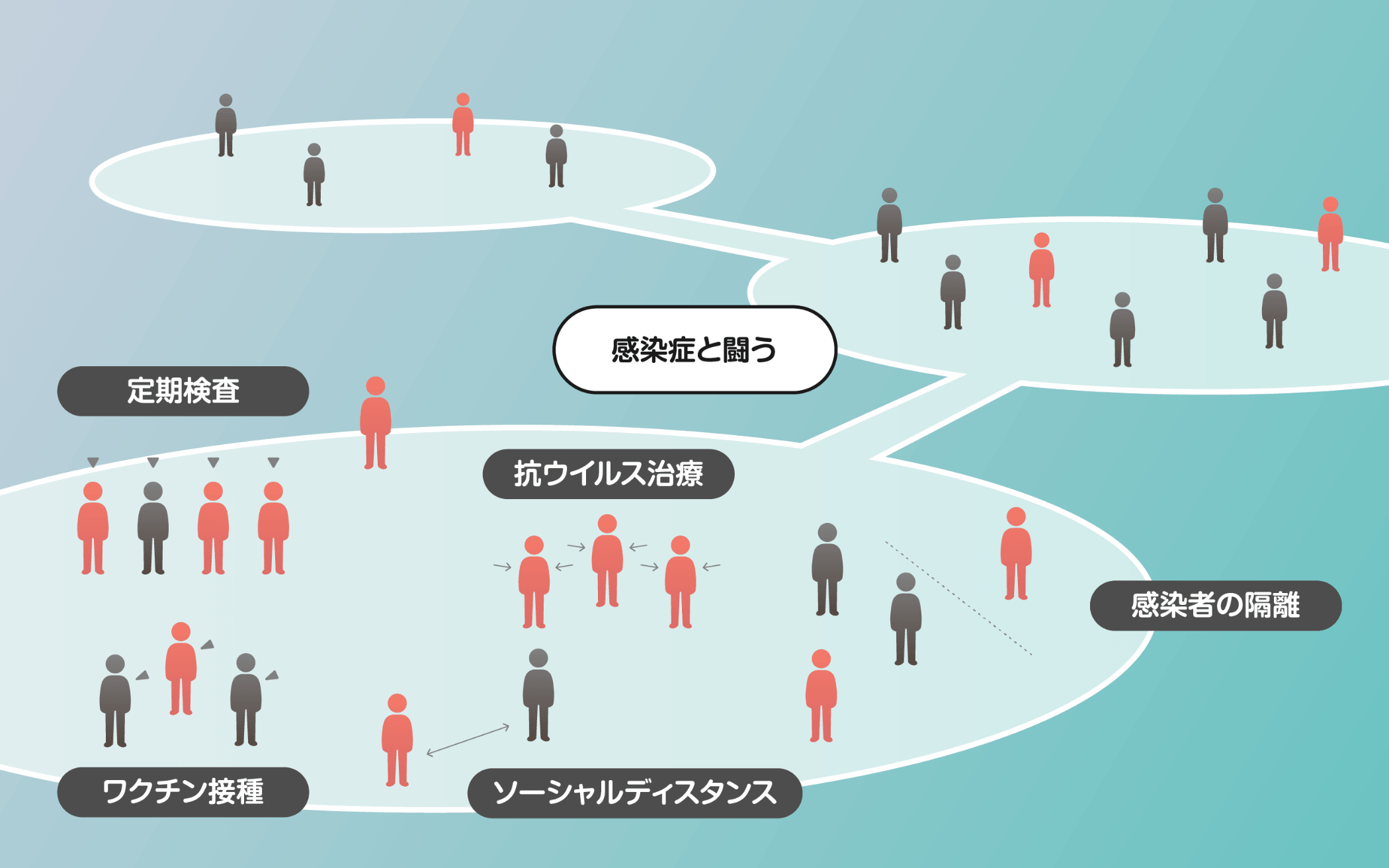
感染症の拡大は、定期検査や隔離政策など、さまざまな感染症対策を導入することで軽減あるいは抑制が可能です。しかし、これらの対策を効果的に活用するためには、科学的根拠に基づき、その効果を評価、事前に予測することが重要です。そのためには、個人レベルのウイルス感染動態に関する数理モデリングや、臨床および実験データを活用したシミュレーションが必要となります。これらのアプローチを通じて、たとえば、感染者を効率的に検出するための最適なスクリーニング戦略や2次感染のリスクを下げる適切な隔離解除のガイドライン、あるいはウイルスの拡散を防ぐために必要な個人間の物理的距離などの課題を定量的に考察することが可能となります。
数理薬理の研究
薬剤の用法・用量と効果、副作用の関係を定量化する数理モデルやシミュレーションの手法は、医薬品の開発や臨床での適正な薬剤使用において欠かせないものとなっています。現在、古典的な薬物動態学や薬力学に加えて、生物学、薬理学、生物統計学、医学などの専門知識に基づいた数理モデルを活用し、実務的に課題解決を目指しつつ、理論的な知見を積み重ねながら発展しつつある学際的な分野です。近年、機械学習を中心とする AI 技術の進化が目覚ましく、創薬研究の分野でも、従来のモデリング&シミュレーションの枠を超えて、AI を含む先端的な数理科学技術を駆使した革新的な研究が急速に台頭しています。その一例として、医薬品開発の効率化を目指す研究が注目を集めています。生体内を精密に再現した数理モデルを用いてバーチャルペイシェント並びにバーチャルポピュレーションの作成と生成を行い、バーチャル空間で臨床試験を実施することで医薬品開発の過程を大幅に短縮し、新薬の迅速な開発に貢献することが期待されています。
私たちは、疾患に関連した実世界データ(Real-World Data)や薬剤の治療効果を評価する数理モデルを活用することで、患者全体又は特定の患者群(例: 高齢者や基礎疾患を有する患者)における有効性や安全性を予測する研究に取り組んでいます。また、疾患進行を定量的に理解することで、治療介入の最適なタイミングや効果を予測でき、臨床試験の実施形態に即した治療目標や期待されるアウトカムを明確に設定しやすくなります。これら、医薬品開発、疾患動態の理解、治療評価の相互補完的な関係を、総合的に扱える異分野融合研究を目指しています。
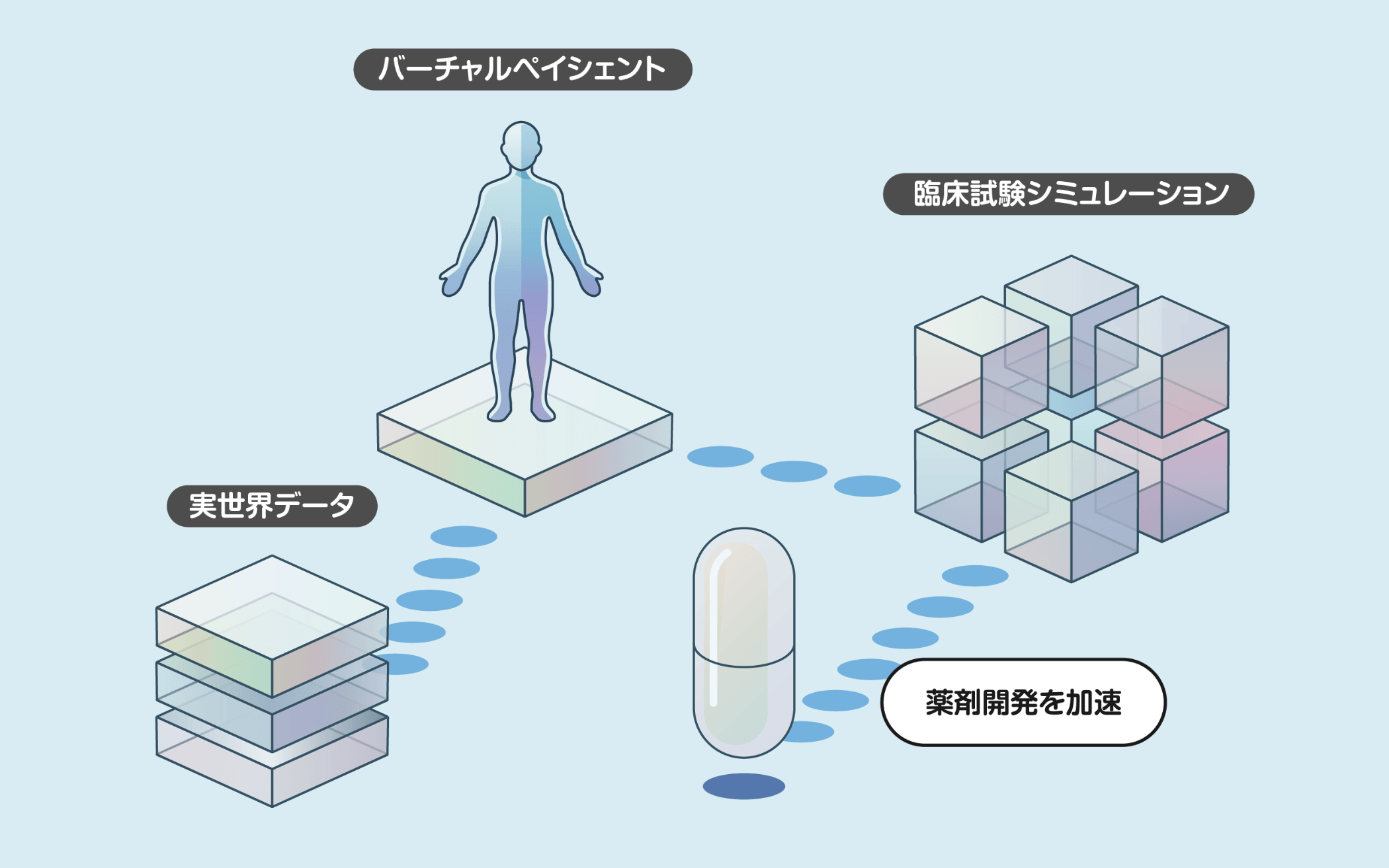
患者の病態進行には個人差があり、治療反応性も患者ごとに大きく異なります。これらのばらつきには多様な因子が関与し、それらが相互に影響を及ぼし合う場合もあります。たとえば、病態進行の動態を明示的に考慮した数理モデルを用いることで、患者間のばらつきを再現した臨床試験のシミュレーションが可能となります。従来の医療統計によるアプローチに加えて、さまざまな治療候補薬の投与スケジュールを網羅的に評価し、本質的に介入による病態変遷の未来予測を伴ったシミュレーションを駆使して、バーチャル空間で臨床試験を評価する in silico ランダム化比較試験(isRCT)のプラットフォームを構築しています。
ウイルスダイナミクスの研究
ウイルスには自身に栄養を取り込んで成長・増殖するという機能はありません。ウイルスが増殖するためには細胞の増殖機構を使う必要があることより、ウイルスは“最も単純な生命体”と比喩されることがあります。しかし、ウイルス感染のダイナミクスを理解することはそれほど容易ではありません。現在のウイルス学では、細胞生物学的・遺伝子工学的・分子生物学的な実験技術を駆使し、感染ダイナミズムの“スナップショット”を観察することに帰着する場合が多いからです。1983 年のヒト免疫不全ウイルスの単離以降、感染ダイナミズムの全貌を理解する必要性が生じ、そのために発展してきた分野があります。ウイルスダイナミクスと呼ばれ「経時的な臨床・実験データを数理モデルやコンピュータシミュレーション、統計的手法を駆使して解析することで、時々刻々と変化する宿主内、細胞内におけるウイルス感染を定量的に理解しようとする分野」として定義されています。私たちのグループでは、イギリス、フランス、カナダ、アメリカ、オーストラリア、韓国、日本などの複数の実験および臨床チームと共同研究することで、様々な種類のウイルス感染のデータを解析しています。そして、抽出した定量的な知見に基づいて、生物学の立場からウイルス感染を理解し、制御・操作することを目指した研究を進めています。

ウイルスの多くは細胞に感染します。ウイルスが細胞内に感染するとRNAやDNAなどの遺伝情報が複製されます。複製された遺伝情報はさらなる複製に使われたり、ウイルスのタンパク質と会合して新規のウイルス粒子として細胞外へ放出されたりします。それぞれの状態にあるウイルスの量や細胞数、タンパク質発現の量を計測した実験データに対してウイルスの細胞への感染と細胞内での複製を考えることができる多階層数理モデルを用いた解析を行うことで、ウイルスの感染戦略や感染の特徴を抽出できます。
がん疾患の研究
わが国の死亡原因の 1 位はがんであり、中でも最も死亡者の多い肺がんでは、年間 8 万人近くが命を落としています。近年の分子標的薬・免疫チェックポイント阻害薬を含む各種薬物療法の目覚ましい進歩により、進行がんの予後はある程度の改善がみられてきました。しかし、治療の過程での獲得耐性や、治療の適用症例の制限など、今なお解決すべき問題が多く残っています。また、国内の女性罹患数が最も高い乳がんでは、手術や放射線治療によってがん病変を取り除けた場合には予後良好です。一方、(診断時に転移がある症例も含む)一部の症例では転移・再発する可能性が高く、これらのがんの病態を明らかにし、制御することが求められています。さらに、固形がんとは対照的に、強力な薬物療法や放射線治療、造血幹細胞移植が奏効する血液がんであっても、成人 T 細胞白血病のように無治療経過観察時に発症した場合、本質的には対処療法しか選択肢のない悪性リンパ腫もあります。
私たちは、ヒトのさまざまな臓器において腫瘍が環境に適応する仕組みをシステムとして解明し、その特性と脆弱性を定量的に分析することで、革新的な治療戦略の創出を目指した研究を進めています。特に、腫瘍の拡大と薬剤耐性集団の出現、治療介入の組み合わせや順序に着目し、実験および臨床データに基づいた網羅的なシミュレーションを行うことで、従来の治療法に対する評価と新規の治療法の提案を可能にしています。また、臨床的転帰と関連付けられた多様な臨床データを活用し、がんの病態進行の定量的理解、予後の超早期予測、治療介入の効果評価、バイオマーカーの探索などにも取り組んでいます。これらの研究を通じて、がんと闘うための新しい知見を蓄積し、個別化医療の実現を目指しています。
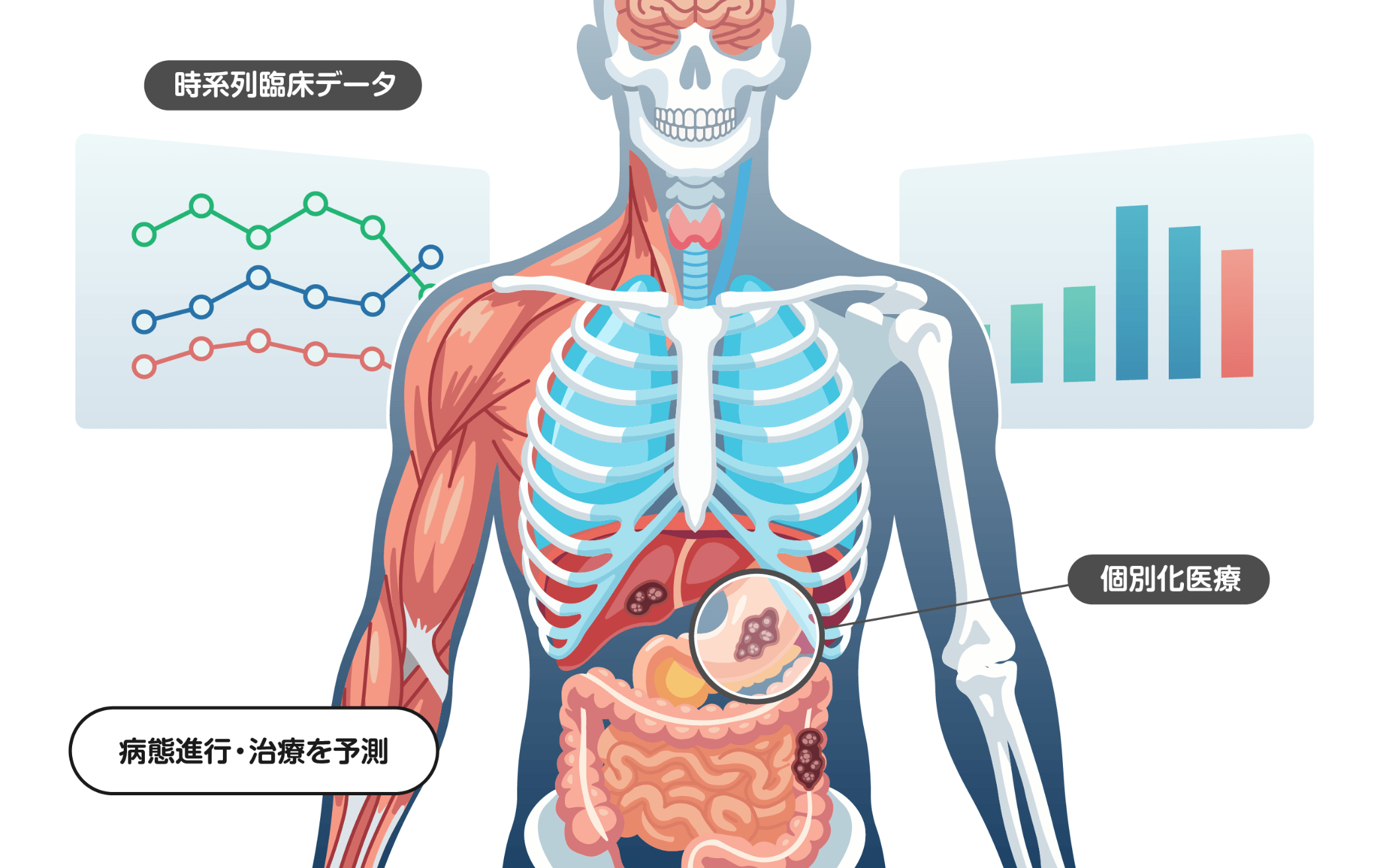
がんは、その種類や罹患部位、患者ごとに異なる進行パターンを示します。時系列の臨床データを解析することで、病態の進行を層別化できる場合があり、進行パターンを説明するメカニズムが解明できる可能性があります。さらに、病態進行を記述する数理モデルを構築できれば、コンピュータシミュレーションにより、治療の効果が高い症例を特定したり、治療効果そのものを個人または集団レベルで定量的に理解したりすることが可能になります。こうしたデータサイエンスの多様な手法を駆使し、理解から予測、さらには実装までを見据えた革新的なアプローチの確立を目指しています。
免疫・細胞分化の研究
生体内の生命現象は主に細胞群のはたらきによるものです。全ての細胞は幹細胞から分化し、徐々にそれぞれの能力を獲得していくことで、一つのシステムとして機能しています。健康な生体内では、細胞群が恒常性を保っていると考えられますが、分裂異常による細胞数の変化や、特定の細胞群の異常な働きによる炎症などのように恒常性の破綻が疾患へとつながります。細胞群の恒常性が破綻する原因には、遺伝子の変異やその発現の変化、病原体の侵入など様々な内的・外的要因が考えられます。生命現象を理解するためには、細胞がどのような順番で分化し、それがどのように制御されているかを明らかにする必要があります。近年では、計測技術が発達したことで、1細胞レベルでの細胞の多様性やそれぞれの細胞の分化履歴を取得することが可能になりました。
私たちは、最新の計測実験から得られるデータから、幹細胞が分化と自己複製を制御し、段階を経て最終的な分化細胞へと分化していく過程を明らかにするための、細胞分化の数理モデルおよびコンピュータシミュレーションの開発を進めています。細胞の分化・増殖および細胞間の相互作用を規定する細胞内での現象を含めた多階層的な数理モデルでの記述によって、分布として観察される細胞群のデータから、多様な個々の細胞とそれらの集団としての振る舞いを理解することを目指しています。特に、造血系の細胞やがんなどの腫瘍を形成する細胞について、自己複製(増殖)・分化能の変化と、それらが生じる遺伝および構造的な因子の探索を行っています。最終的には、多細胞で構成された生体が成立し、機能しうる機序と、破綻する要因を包括的に理解し、関連する疾患に対する新たな治療法や予防戦略の構築に貢献したいと考えています。
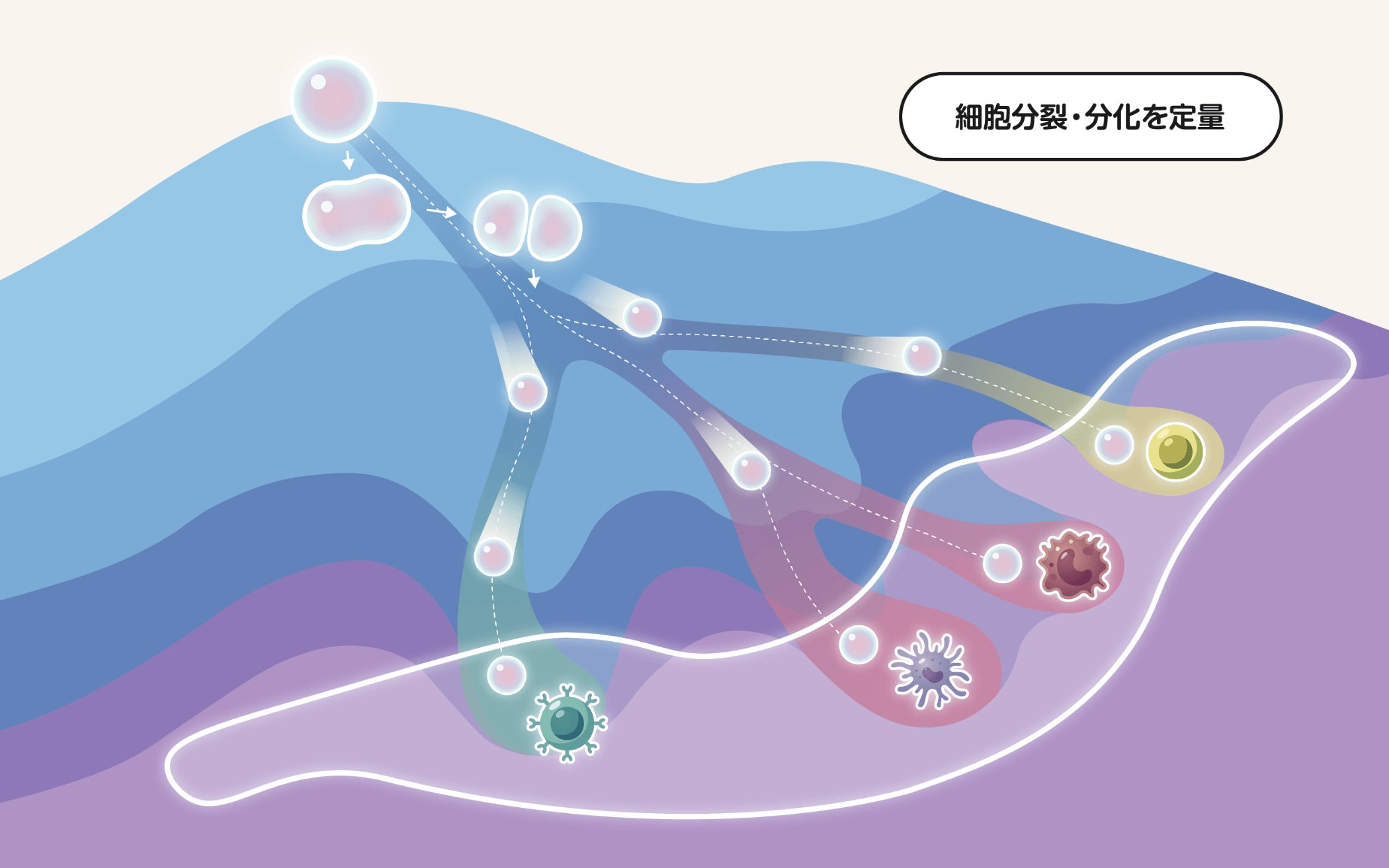
細胞分化ダイナミクスを記述する数理モデルを用いて、さまざまな計測データから、細胞分化のメカニズムや恒常性を維持に重要な要素の抽出、加齢や遺伝子変異の獲得などでの分化様式や細胞群の変容の解明を進めています。細胞分化を理解するためには、幹細胞集団の分化様式の調節機序や、各細胞系統への分化と細胞系統内での分化の制御などの、階層の異なる細胞分化ダイナミクスを考える必要があります。数理モデルや統計的手法による解析で細胞分化の統合的な理解を目指しています。
研究のキーワード
研究の対象:新興感染症、新型コロナウイルス感染症、エムポックス、真菌症、HIV/AIDS、B 型肝炎、急性肝不全、急性肝疾患、生体肝移植、前立腺がん、乳がん、肺がん、大腸ポリープ、大腸がん、副腎偶発腫瘍、成人 T 細胞白血病、精神疾患、自閉スペクトラム症、網膜色素変性症、ワクチン、抗ウイルス薬、抗真菌薬、科学コミュニケーション
研究の方法:数理モデル、コンピュータシミュレーション、人工知能(機械学習、深層学習)、統計解析(一般化線形モデル、非線形回帰、非線形混合効果モデル)、個体群動態、バーチャルペイシェント、科学コミュニケーション、拡張現実(XR)、VTuber
研究のデータ:細胞数、抗体価、血液検査データ、用量反応データ、ウイルス量、薬剤濃度、症状、メタボロームデータ、医用画像、カルテデータ(治療、転帰)、アンケートデータ、患者数、患者背景、MRI
研究の分野:数理生物学、理論生物学、データサイエンス、統計科学、応用数学、人工知能学、ウイルス学、感染症疫学、精神医学、内科学、腫瘍生物学、定量薬理学、計量生物学、生物物理学、細胞生物学、免疫学、バイオインフォマティクス
研究の目的:生物学的機序の解明、最適治療の提案、臨床転帰の予測・制御、患者数の予測・制御、臨床試験のデザイン、行動規範・指針(ガイドライン)の提案、適切な科学情報の提供